In our last post, There’s A Better Way To Classify Search Intent, we explained how Content Harmony’s new software for SEOs and content marketers is detecting search intent as part of the keyword research process.
But, understanding search intent is only one factor in understanding how to get your content to rank well for a specific query in Google search results.
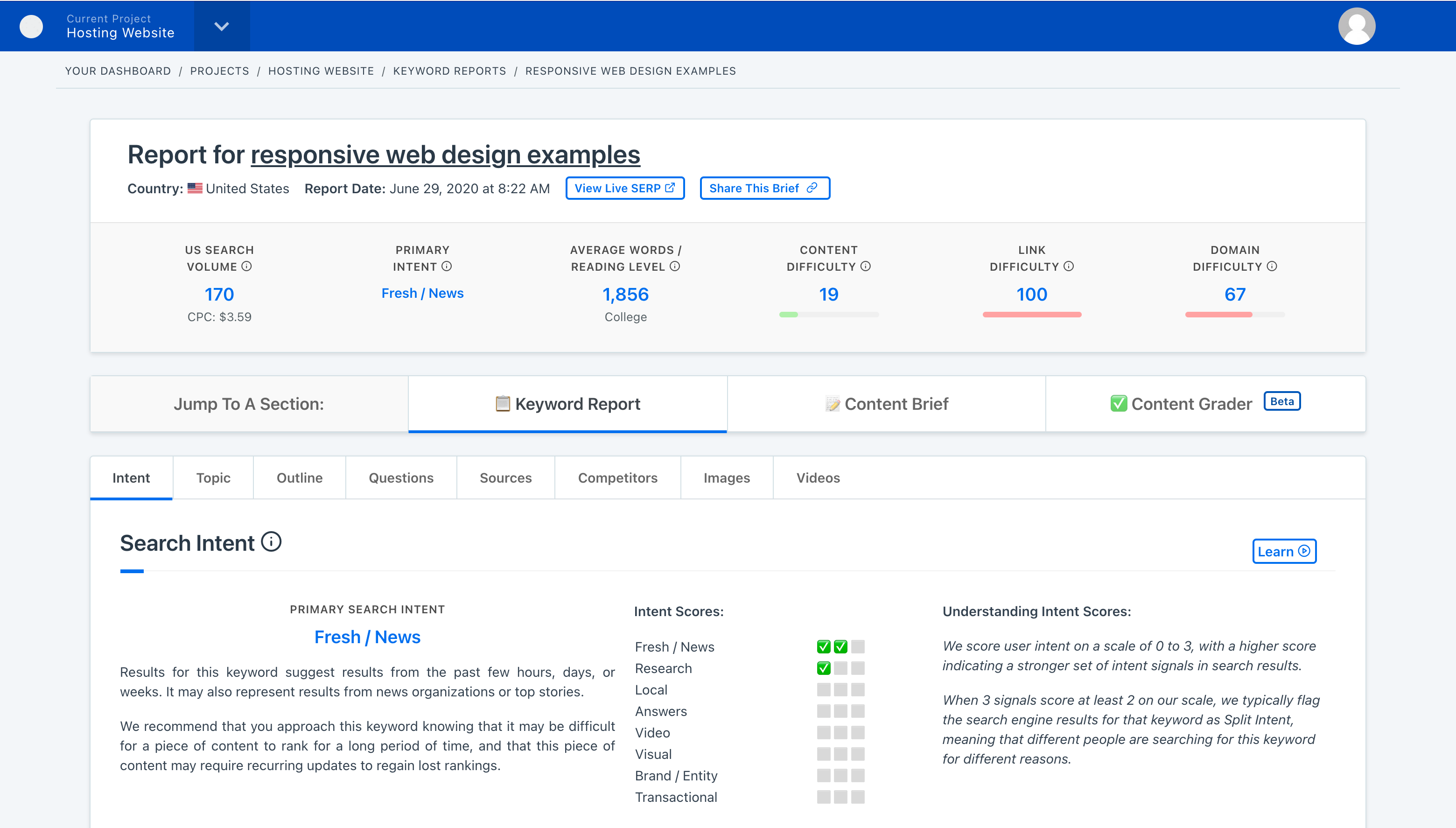
One of the features we’re really excited about is how we’re approaching the concept of Keyword Difficulty in our new toolset.
TLDR – We’ve released a new three-part keyword difficulty scoring model that factors in Content Difficulty, Link Difficulty, and Domain Difficulty as distinct concepts that help you quickly understand why a keyword is easy or difficult.
This may not matter when you’re analyzing 10,000 keywords at a time, but when you’re working your tail off to produce content for one really important keyword (the problem our software is trying to solve), knowing everything you can about that keyword quickly is super important.
So – why release a new approach to keyword difficulty? What’s not working with other solutions already out there?
A Short History of Keyword Difficulty Metrics
SEOs have a long history of trying to measure keyword difficulty.
One of the earlier well-used examples was Moz’s original keyword difficulty rating. This forum post from 2012 explains how it was measured (via Archive.org), but to quote Nick’s reply on that page, it factored in “everything from on page scores, links metrics, and rank to calculate the difficulty of a KW.”

Do you guys remember how awesome those butterfly charts were?? I would stare at them like they were magic. I was always that tiny DA 12 site at #8 trying to figure out how that DA 25 site at #5 got there. I shoulda spent that time building links, but, I digress. [screenshot via old Q&A thread via archive.org]
This was a pretty good start and better than any other options out there, but, it didn’t always produce results that SEOs could rely on to know how hard it would be for them to rank for a given keyword. Rand himself wrote an assessment of the good and bad points of this keyword difficulty score in a 2017 post on the Moz Community Forums (via Archive.org).
Still, it was better than other solutions out there aside from building your own keyword difficulty models in Excel that accounted for the ranking factors you cared about most.
Fast forward a few years….
Enter Ahrefs’ Keyword Difficulty Scores
Ahrefs’ Keyword Difficulty was pretty awesome when it launched because it focused exclusively on links to the URLs on page one of a SERP for the keyword that you’re analyzing. I like this because it’s very clear how the score is calculated, and from a practical perspective, it gives us a decent idea of how hard it will be to rank without proactive link building efforts.
Because of that, it’s currently the score we use most frequently when doing keyword research for clients.
But, we’ve encountered gaps in this links-only approach. It often flags very difficult keywords as easy, because it doesn’t factor in SERPs that are extremely difficult to rank for due to non-link reasons. This is a search intent problem most commonly, where links are not the dominant ranking factor.
Take these examples of high volume keywords with KD under 10 and you can see this in effect:

As you can see, there are some search queries in here that only a handful of sites could reasonably rank for.
I guarantee you that you’re not going to rank in the top 4 results for “Buy Buy Baby” (against buybuybaby.com, twitter.com, yelp.com, and retailmenot.com) just by building more links and creating a well targeted page. A Keyword Difficulty score of 9 is deceptive here.
But, these types of keywords often slip into your keyword research when you’re dealing with thousands of keywords at a time, and they require lots of manual filtering to remove them from a spreadsheet of good opportunities.
As I said above, we really like the Ahrefs KD score and use it frequently. But these examples are a big part of the reason we’ve been considering more advanced ways to measure keyword difficulty across all types of SERPs – not just link-driven ones.
Moz’s New Keyword Difficulty Score
Moz’s relaunched their Keyword Difficulty scores in 2017. From what I can see, Moz has made a lot of improvements to their old scoring system. Their link data quality has improved drastically, and their use of clickstream data allows them to understand click-through rate of a keyword that may or may not be worthwhile to try and target
But – it’s really difficult for me to get on board with using it because of the underlying concept in how it’s created: it blends a large number of factors together (via Archive.org) in a way that hides the reason the keyword earned a particular score. To me this is a deal killer because it just doesn’t explain why a keyword is hard to rank for. What if it’s hard to rank for because there are lots of high authority domains, but I’m publishing on a site that’s DA 80?
This isn’t a knock against the Moz team. They have multiple team members working on this product that are incredibly smart and have each been working on internet-wide keyword research 10x longer than I have. And, they are building for a much different audience – they’re looking to serve 100k to 1 million marketers – I’m looking for data that will serve 1k to 2k top-of-their-field SEOs and content marketers who have different needs.
Other attempts from SEO toolsets that I’ve seen of measuring keyword difficulty just haven’t stuck, mostly due to prioritizing what I believe are the wrong data inputs, using datasets that are unreliable or not comprehensive enough, or overly favoring factors that in my experience don’t make much of a difference. If I can’t trust your underlying data, I can’t trust your metrics.
The problem with looking at Keyword Difficulty as a single number between 0-100 is that it doesn’t clearly tell you *why* a keyword is hard to rank for. Using one-metric-to-explain-it-all for keyword difficulty creates more confusion for the analyst or marketer trying to understand a given search result.
I believe that the answer to fixing this is to divide Keyword Difficulty into multiple metrics – different types of difficulty, specifically.
We’ve done this in our new toolset by splitting Keyword Difficulty into a set of 3 types of difficulty, each on a scale of 0-100:
- Content Difficulty – how keyword-targeted and optimized the top ranking pages are.
- Link Difficulty – how many links the average page one result has to that exact page.
- Domain Difficulty – the average Domain Authority/Rating the page one results have.
By doing so we’re able to give users a clear picture for whether they’re up against big sites, whether they’re up against highly linked pages, and whether they’re up against highly targeted pages. You should be able to look at our 3 metrics and know why a keyword is going to be easy or hard to rank for.

A live screenshot of what these Difficulty scores look like side by side in the Content Harmony toolset. In this example, we’re looking at a SERP that is dominated by large sites (high Domain Difficulty) with moderately well-targeted pages of content (medium Content Difficulty), but low-to-medium Link Difficulty. I would approach this keyword differently if I was a new site versus a big established domain.
Let’s jump in to how we’re calculating each of these scores:
Content Difficulty
This is probably the most complex of the three difficulty scores, but in essence, we’re grading the page one results of a SERP for a basic on-page SEO grade.
We look at a “brute force keyword match” analysis of each page ranking on page 1, and then score them.
- Is the keyword (or a close variant) in the title tag?
- Is the keyword (or a close variant) in the URL?
- Is the keyword (or a close variant) in the H1?
- Is the keyword on the page multiple times?
We’re also looking at the following rough content quality metrics, though at a slightly lower weight than keyword targeting:
- What is the average word count?
- Are there photos/images on the page?
- Are there videos on the page?
A lot of people might suggest that such a basic look at keyword targeting and things like content length is too simplistic. I fully expect this difficulty score to be the one that earns the most pushback and disagreement. But, even though we intend to evolve this score over time, we believe that keeping this rating simplistic is for the better.
Why?
We want to tell SEOs and content producers how closely matched the results on page 1 are. If there are 10 sites with highly optimized pages for that exact keyword, we want to know that quickly, and looking at top ranking factors like keyword usage throughout the page is a reliable way to do that.
What Does A High Content Difficulty Look Like?
For instance, take a search like [best small business crms]:

Highly targeted content for [best small business crms]
An example like [best small business crms] would have a high Content Difficulty score, because the SERP is full of exact-match content that is perfectly optimized to rank for this query. These pages are almost all long form, with multiple images/screenshots, and high focus on keyword usage throughout the content. We would expect to return a Content Difficulty score between 70 to 100 for a search result like this.
While the rest of our toolset uses more advanced methods of content topic and entity analysis, we feel a raw partial-match or exact-match approach presents a clearer picture of Content Difficulty.
Furthermore, if Google is trying to match user intent more than they are trying to rank pages with exact match keyword targeting, we want that to show up in our reports. A search result with low exact match keyword targeting *should* score lower on content difficulty, so that you focus more heavily on other factors like search intent.
Link Difficulty
Simply put, this is an estimate of how much link building or link earning you’ll need to do to be competitive with the other results on page one.
This is most closely related to Ahrefs Keyword Difficulty, which is also based on page-level links.
To calculate this score, we’ll take the number of linking domains to each result on the page and average them, then normalize that on a scale of 0-100. We’re also testing scores where we toss out outliers that would skew the mean.
I go into more detail below on link data sources, but our initial plan is to use Moz’s linking domains metric for calculating Link Difficulty.
What Does A High Link Difficulty Look Like?
This search result for [time tracking software] is a good example:

High Link Difficulty from [time tracking software] due to lots of highly linked homepages.
Because it’s a popular and competitive search phrase, and particularly because many of the results are homepages that are likely to have lots of links, we would expect to see a fairly high Link Difficulty score around 70-100 for this keyword.
As a comparison, Ahref’s Keyword Difficulty (which is also entirely based on page-level links) for [time tracking software] is scored as a 72.
Domain Difficulty
Much like link difficulty analyzes page-level links, with domain difficulty we’re taking domain-wide link metrics and averaging them across the page one results.
In this case we’ll roughly be reporting an average Domain Authority as measured by Moz, since it has already been normalized on a 0-100 scale to represent domain’s link authority as compared to all other domains on the internet. We also show the lowest DA score in the top page of results, which you can also find in the competitor analysis section of our reports.
On search results that score low on both link difficulty and content difficulty, but highly on domain difficulty, we want to make sure that users understand smaller domains still may be up against some tough competitors when trying to rank for this keyword (then again – sometimes SERPs are filled with big domains that poorly target a keyword because nobody else has done a good job of targeting that keyword yet. That’s up to you the SEO Strategist to decide).
A good example of low Link & Content Difficulty but high Domain Difficulty? Branded search results (which our intent detection would also flag as branded)
What Does A High Domain Difficulty Look Like?
Let’s say you search for [coca cola website]:



Our reports will accurately rate this keyword’s search intent as “Branded”, and you’ll also see a very high Domain Difficulty. That’s because the domains ranking for this search phrase, like coca-cola.com, Wikipedia, Linkedin, Facebook, and other branded sites like https://www.worldofcoca-cola.com, are all highly authoritative.
Those pages may not be highly targeted to the user’s query, and they may not have a ton of links themselves, but that doesn’t mean this is an easy keyword to rank for.
Using a phrase like [coca cola website] is an easier example since the intent behind ‘website’ is clearly branded, but this type of search result is common with most branded search results, since Google wants the user to be able to find pages like social profiles and other official branded webpages. Try searching for a smaller company name like [content harmony] and you’ll still see high authority results like Facebook, Twitter, Glassdoor, and so on.
We spot this all the time while doing keyword research for clients where what appears to be a normal unbranded keyword is actually somebody’s brand name, especially in markets where there are lots of generic names or exact match domains used. While doing keyword research, we wouldn’t want that keyword to slip into a list of recommendations for blog posts to prioritize because the keyword looks “easy” according to page-level link metrics, and has abnormally high search volume (because of people searching for the brand name).
Where Are We Getting Our Link Data?
The primary two sources I trust for my own team are Moz’s newly relaunched link data and Ahrefs. A bunch of SEOs I respect also use Majestic heavily but I’ve never been able to make it work with my workflow.
Our plan for Content Harmony’s toolset is to integrate Moz’s link data directly into our toolset, and we also plan to allow users to add their own Ahrefs API credentials if they want to augment the data. Ahrefs doesn’t allow their data to be sold directly to other tool providers, otherwise we would just pull data from both sources.
Want To Take It For A Spin?
These difficulty metrics come standard in Content Harmony's content brief workflow.
Get your first 10 credits for just $10, or schedule a demo and we'll give you free access.
Want to see how Content Harmony helps you build content that outranks the competition?
The blog post you just read scores Good in our Content Grader for the topic "keyword difficulty".

Grade your content against an AI-driven topic model using Content Harmony - get your first 10 credits for free when you schedule a demo, or sign up here to take it for a spin on your own.
✉️ Get an email when we publish new content:
Don't worry, we won't bug you with junk. Just great content marketing resources.

Ready To Try
Content Harmony?
Get your first 10 briefs for just $10
No trial limits or auto renewals. Just upgrade when you're ready.
You Might Also Like:
- Content Marketing Budget Examples For All Business Sizes
- A Complete Freelance Hiring Checklist For Marketers
- How To Produce Great Conference Coverage
- 5 Skills Brands Need To Learn From Publishers
- Email Split Testing Ideas
- How To Optimize eCommerce Product Pages
- How To Optimize eCommerce Category Pages
- This Is What Great Content Looks Like
- Content Success Factors for SEO
- Keyword Research for the Complete Customer Lifecycle
- 8 Reasons Journalists Make The Best Content Marketing Writers
- The Hourglass Sales Funnel
- eCommerce Blog Examples That Can Actually Generate Sales
- What Is A Content Brief (And Why Is It Important)?
- How To Update & Refresh Old Website Content (And Why)
- How to Create a Content Marketing Strategy [+ Free Template]
- How To Create Content Marketing Proposals That Land The Best Clients
- How To Write SEO-Focused Content Briefs
- How To Create A Dynamite Editorial Calendar [+ Free Spreadsheet Template]
- The Keyword Difficulty Myth